问题及回答记录
| 问题及回答记录 (self-test Q&A related to your experience reports, and no less than 5 questions or contents of Q&A nearly full of the sheet as well as handwriting required) |
|---|
1. 输入net view 192.168.0.1查看共享资源时为什么显示了错误代码53?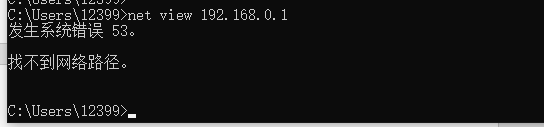 |
| 回答:通过查询,错误代码53的原因主要有5个,分别时: ①IP地址错误; ②目的标未开机或者下了网络,拔了局域网线,也有可能是关了服务器; ③目标LanManServer服务未启动; ④目标有防火墙(端口过滤); ⑤由于netbios over tcp/ip和dns造成的; ⑥端口没有开放; |
2.为什么输入指令net view查看局域网内的主机名时显示系统错误6118,工作组服务器列表无法使用?应当如何解决?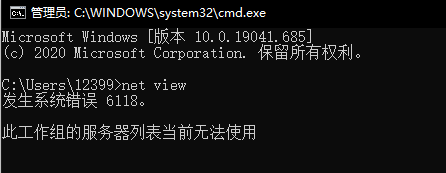 |
| 回答:原因:在家庭或办公室网络的网络连接上启用防火墙,就有可能会发生这种现象。默认情况下,防火墙会关闭用于文件和打印共享的端口,以防止 Internet 计算机连接到计算机上的文件和打印共享。 解决方案:关闭电脑的防火墙,进入services.msc启动Computer Browser即可。 |
3.在TCP的流量控制分析中,慢启动本应该从1开始,但是为什么抓的包中显示慢启动过程中不是从1开始,而是从46开始的,是不是技术更新了? 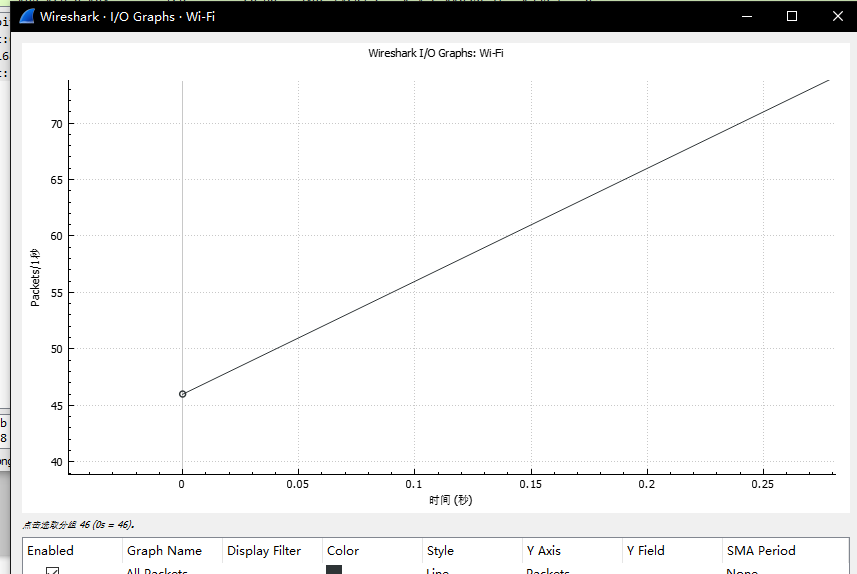 |
| 回答:通过反复测试发现,并不是技术更新了,而是在抓包过程中,计算机的网络除了用于上传文件,其他的应用进程可能也在使用网络,但是whireshark统计的是整个网卡的I/O流,因此抓包时的流量除了我们需要的上传文件,还有其他进程,比如QQ微信也在使用网络,所以慢启动看起看并没有从1开始。实际上传输文件的这些网络活动中仍然是慢启动,是从1开始的。 |
| 4.在使用TCP和UDP中,使用的都是IP地址,根据IP地址找到对应的MAC会浪费时间,为什么不直接使用硬件地址MAC进行通信,而要使用抽象的IP地址并调用ARP来寻址? |
| 回答:由于全世界存在着各式各样的网络,它们使用不同的硬件地址,要使这些异构的网络进行通信就必须进行非常复杂的,硬件地址转换工作,因此由用户或主机来完成这项工作几乎是不可能的,统一IP地址就把这个问题解决了。 |
| 5. 在RIP 协议中,如果原来路由表和新路由表目的网络和下一跳路由相同,但是更新了跳数有可能比原来更大,为什么要直接更新,原来跳数更少不是更快吗? |
| 回答:原来路由表和新路由表目的网络和下一跳都相同,说明路由转发的路径方向是没有改变的,改变的是这条链路上路由的路由器数量,但是这条链路上的路由数不断更新,所以此时不应该选择最小的跳数而应该选择最新的跳数,确保路由信息是最新的信息。 |
| 6. RIP协议是如何避免环路? |
| 回答:一般来说,避免环路的方法主要有6种: 1.定义最大值; 2.水平分割技术; 3.路由中毒; 4.反向路由中毒; 5.控制更新时间; 6.触发更新 1.定义最大值: 距离矢量路由算法可以通过IP头中的生存时间(TTL)来 纠错,但路由环路问题可能首先要求无穷计数。为了避免这个延时问题,距离矢量协议定义了一个最大值,这个数字是指最大的度量值(如rip协议最大值为16),比如跳数。也就是说,路由更新信息可以向不可到达的网络的路由中的路由器发送15次,一旦达到最大值16,就视为网络不可到达,存在故障,将不再接受来自访问该网络的任何路由更新信息。 2.水平分割: 一种消除路由环路并加快网络收敛的方法是通过叫做“水平分割”的技术实现的。其规则就是不向原始路由更新的方向再次发送路由更新信息(个人理解为单向更新,单向反馈)。比如有三台路由器ABC,B向C学习到访问网络10.4.0.0的路径以后,不再向C声明自己可以通过C访问10.4.0.0网络的路径信息,A向B学习到访问10.4.0.0网络路径信息后,也不再向B声明,而一旦网络10.4.0.0发生故障无法访问,C会向A和B发送该网络不可达到的路由更新信息,但不会再学习A和B发送的能够到达10.4.0.0的错误信息。 3.路由中毒(也称为路由毒化): 定义最大值在一定程度上解决了路由环路问题,但并不彻底,可以看到,在达到最大值之前,路由环路还是存在的。为此,路由中毒就可以彻底解决这个问题。其原理是这样的:假设有三台路由器ABC,当网络10.4.0.0出现故障无法访问的时候,路由器C便向邻居路由发送相关路由更新信息,并将其度量值标为无穷大,告诉它们网络10.4.0.0不可到达,路由器B收到毒化消息后将该链路路由表项标记为无穷大,表示该路径已经失效,并向邻居A路由器通告,依次毒化各个路由器,告诉邻居10.4.0.0这个网络已经失效,不再接收更新信息,从而避免了路由环路。 4.反向中毒(也称为毒化逆转): 结合上面的例子,当路由器B看到到达网络10.4.0.0的度量值为无穷大的时候,就发送一个叫做毒化逆转的更新信息给C路由器,说明10.4.0.0这个网络不可达到,这是超越水平分割的一个特列,这样保证所有的路由器都接受到了毒化的路由信息。 5.控制更新时间(即抑制计时器): 抑制计时器用于阻止定期更新的消息在不恰当的时间内重置一个已经坏掉的路由。抑制计时器告诉路由器把可能影响路由的任何改变暂时保持一段时间,抑制时间通常比更新信息发送到整个网络的时间要长。当路由器从邻居接收到以前能够访问的网络现在不能访问的更新后,就将该路由标记为不可访问,并启动一个抑制计时器,如果再次收到从邻居发送来的更新信息,包含一个比原来路径具有更好度量值的路由,就标记为可以访问,并取消抑制计时器。如果在抑制计时器超时之前从不同邻居收到的更新信息包含的度量值比以前的更差,更新将被忽略,这样可以有更多的时间让更新信息传遍整个网络。 6.触发更新: 正常情况下,路由器会定期将路由表发送给邻居路由器。而触发更新就是立刻发送路由更新信息,以响应某些变化。检测到网络故障的路由器会立即发送一个更新信息给邻居路由器,并依次产生触发更新通知它们的邻居路由器,使整个网络上的路由器在最短的时间内收到更新信息,从而快速了解整个网络的变化。但这样也是有问题存在,有可能包含更新信息的数据包被某些网络中的链路丢失或损坏,其他路由器没能及时收到触发更新,因此就产生了结合抑制的触发更新,抑制规则要求一旦路由无效,在抑制时间内,到达同一目的地有同样或更差度量值的路由将会被忽略,这样触发更新将有时间传遍整个网络,从而避免了已经损坏的路由重新插入到已经收到触发更新的邻居中,也就解决了路由环路的问题。 新信息,包含一个比原来路径具有更好度量值的路由,就标记为可以访问,并取消抑制计时器。如果在抑制计时器超时之前从不同邻居收到的更新信息包含的度量值比以前的更差,更新将被忽略,这样可以有更多的时间让更新信息传遍整个网络。 |
| 7.UDP协议比TCP协议更快,并且UDP还不需要三次握手,但是为什么大多数应用软件仍然采用的是TCP协议? |
| 回答:其实两种协议并没有好坏之分,应用程序采用哪种协议需要具体问题具体分析,要根据用途来选择具体的协议,或者说两种协议都用。通过计算机网络的学习知道UDP的特点是无连接的,有单播、多播、广播的功能,是面向报文的,不可靠的,头部的开销小。TCP的特点是面向连接的,只支持单播传输,面向字节流,是可靠传输,有拥塞控制功能,提供全双工通信。因此在开发一个应用程序时,需要先设想好该程序有哪些特点,再根据程序特点选择具体的协议。 |
| 8. OSPF与RIP两者有什么区别? |
| 回答:RIP协议是一种传统的路由协议,适合比较小型的网络,但是当前Internet网络的迅速发展和急剧膨胀使RIP协议无法适应今天的网络。OSPF协议则是在Internet网络急剧膨胀的时候制定出来的,它克服了RIP协议的许多缺陷。RIP是距离矢量路由协议;OSPF是链路状态路由协议。 |
实验内容
一、常用的网络命令分析
1. 查询DNS、IP,mac地址及DHCP服务的情况
(1)实验步骤:
①打开电脑的cmd;
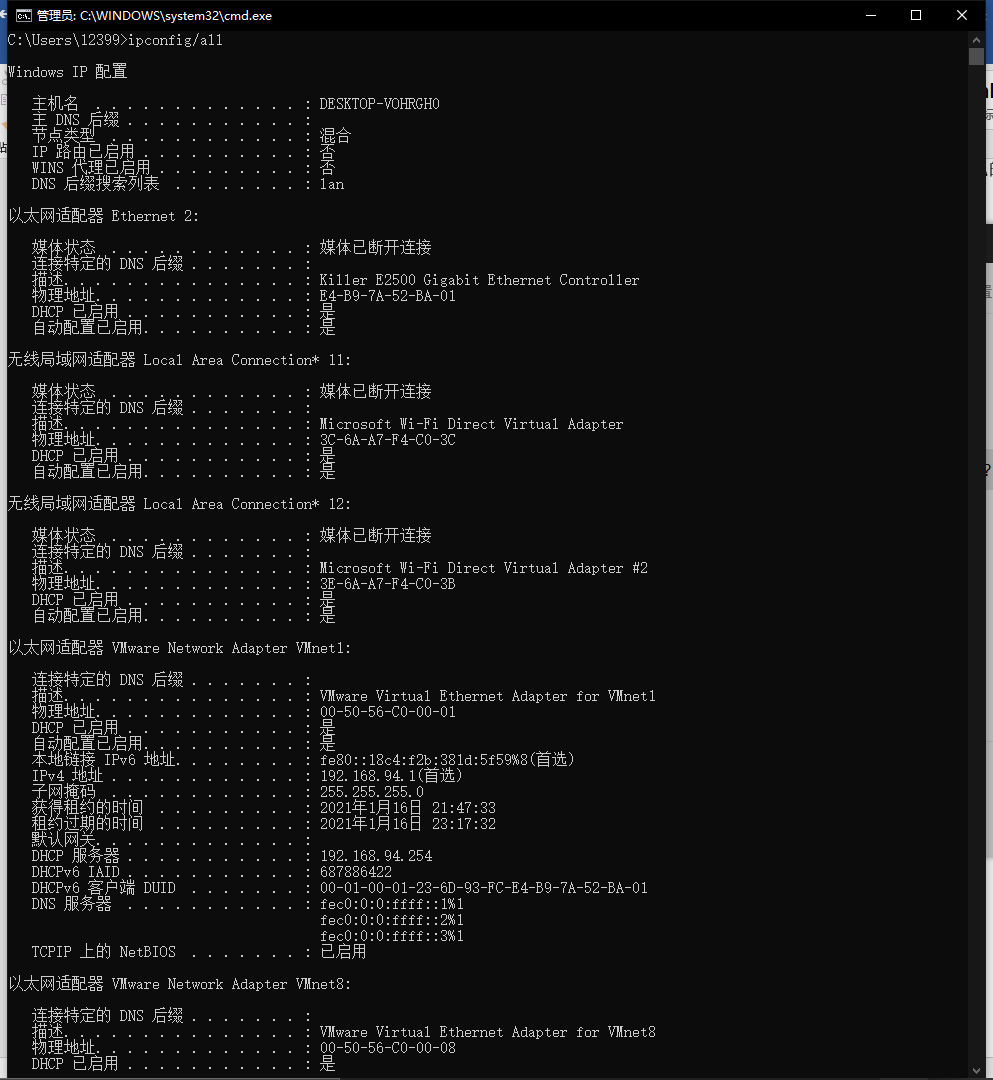
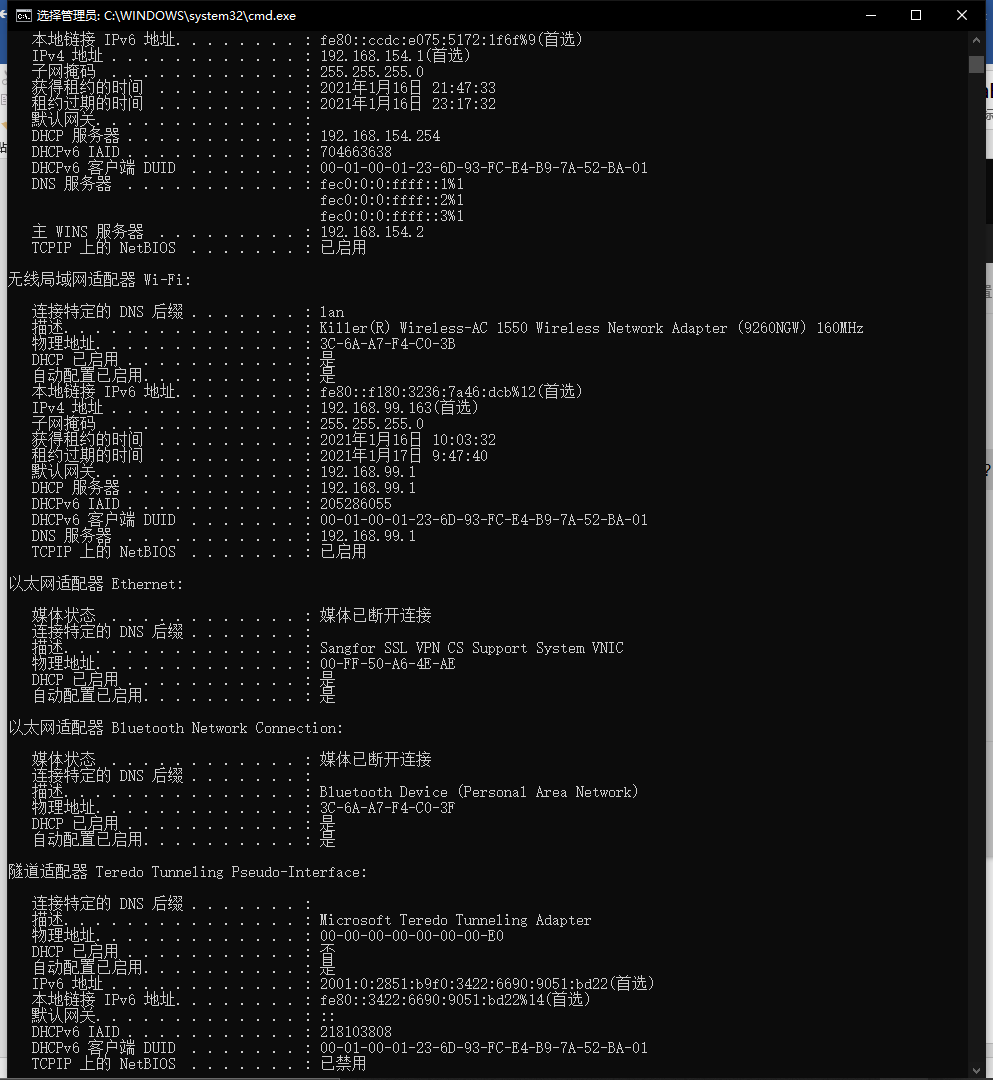
②在cmd中输入命令ipconfig/all,回车后获取该主机所有的网络相关信息。
 )
)
(2)分析:
①从图中可以看出这台笔记本启用的是网络是无线局域网适配器 Wi-Fi;
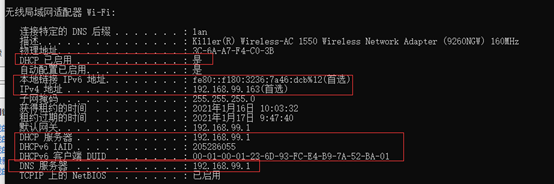
②DNS服务器的地址为192.168.99.1;
③主机的IPv6地址为fe80::f180:3236:7a46:dcb%12,IPv4地址为192.168.99.163;
④MAC地址即物理地址为3C-6A-A7-F4-C0-3B;
⑤DHCP的服务已经启用,DHCP的服务器为192.168.99.1,DHCPv6 IAID为205286055,DHCPv6客户端DUID为00-01-00-01-23-6D-93-FC-E4-B9-7A-52-BA-01;
2.查看ARP表:MAC地址与IP地址的映射表
(1)实验步骤:
①打开电脑的cmd;
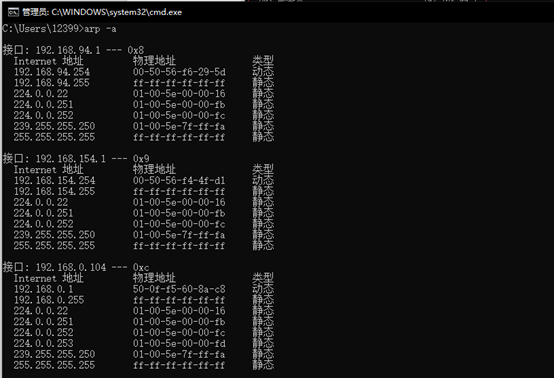
②在cmd中输入命令arp -a,回车后查看主机的ARP表。
(2)分析:
①:一共有3个接口,分别为192.168.94.1 — 0x8、192.168.154.1 — 0x9和192.168.0.104 — 0xc;
②通过查看3个接口的MAC地址与IP地址的映射表,可以看到每个接口的第一个为动态类型,后面的都为静态类型。从表中可以直接看到ARP表的具体信息,每个MAC地址对应一个IP地址。
3. 查看共享资源
(1)实验步骤:
①打开电脑的cmd;
②在cmd中输入命令net view 192.168.0.104,回车后查看ip地址为192.168.0.104网络共享资源。

(2)分析:
通过图中可以看到该ip地址的主机没有上传网络共享资源。
4. 查看局域网内的主机名
(1)实验步骤:
①打开电脑的cmd;
②在cmd中输入命令net view,回车后查看局域网内的所有主机名。

(2)分析:
通过图中可以看到局域网内的主机名只有一个,为“\\DESKTOP-VOHRGHO”。
5. 查看用户列表
(1)实验步骤:
①打开电脑的cmd;
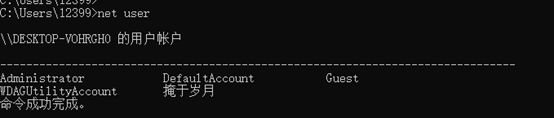
②在cmd中输入命令net user,回车后查看局域网内的用户列表。
(2)分析:
通过图中可以看到局域网内的用户列表只有一个,为“掩于岁月”。
6. 路由跟踪命令
(1)实验步骤:
①打开电脑的cmd;
②在cmd中输入命令tracert www.baidu.com,跟踪百度的路由信息。
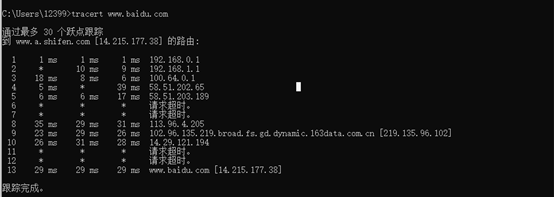
(2)分析:
通过图中可以一共跟踪了13个www.a.shifen.com [14.215.177.38] 的路由,其中有4个超时了,剩下的9的都显示了路由跟踪的具体信息。延迟最低为1ms,最高为39ms。
7. 查看共享资源
(1)实验步骤:
①打开电脑的cmd;
②在cmd中输入命令net share,查看网络的共享资源。
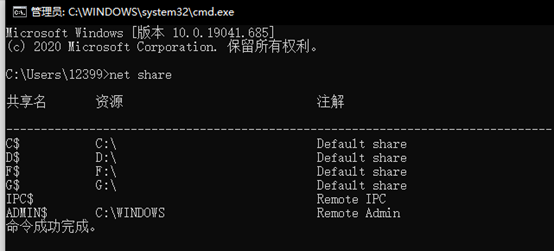
(2)分析:
通过图中可以看出本主机并没有网络共享资源。
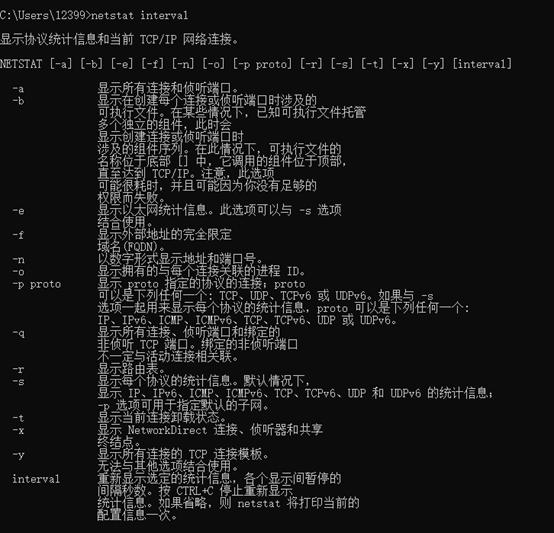
8. netstat的相关操作
(1)实验步骤:
①打开电脑的cmd;
②在cmd中依次输入命令netstat -a(-b、-e、-f、-n、-o、-p proto、-q、-r、-s、-p、-t、-x、-y、interval),查看每个指令的具体功能;
(2)分析:
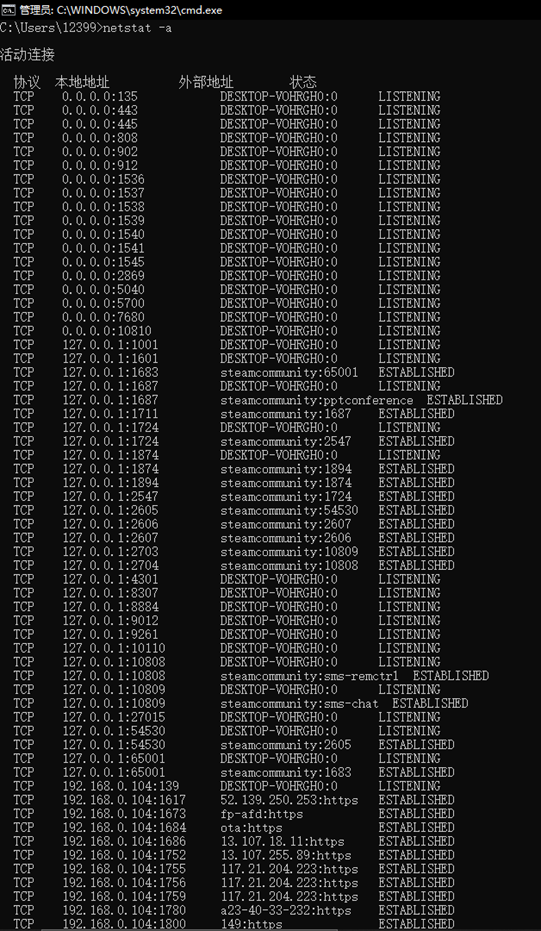
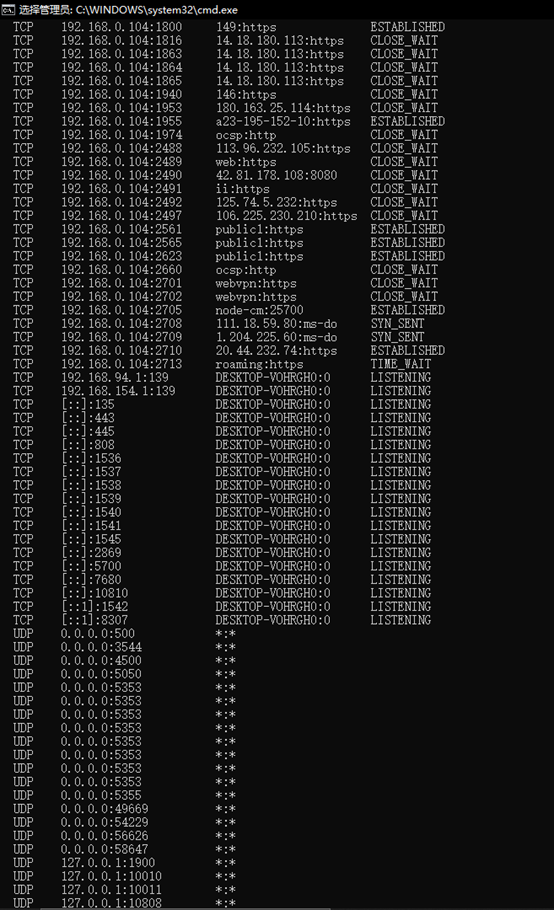
1.输入netstat -a后,显示了所有连接和侦听端口,可以看到每个活动连接的信息一共有协议、本地地址、外部地址和状态四个方面的内容。所有活动连接的协议一共有TCP和UDP两种,状态有LISTENING、ESTABLISHED、CLOSE_WAIT、SYN_SENT这几种。
2.输入netstat -b后,显示了在创建每个连接或侦听端口时涉及的可执行程序,执行命令后可以看出有哪些应用在使用网络并处于什么状态,例如程序NVIDIA Share.exe就处于ESTABLISHED的状态,说明该进程的连接已经建立。
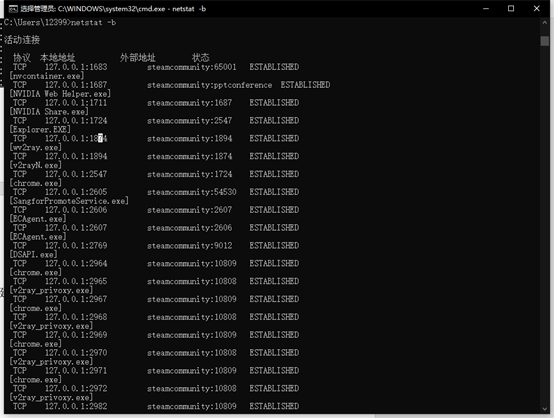
3.输入netstat -e后,显示以太网统计信息,可以看出以太网接受了366845520个字节、399582个单播数据包和1476个非单播数据包。发送了128446546个字节,346964个单播数据包和4257个非单播数据包,但是有一个发送出现了错误。
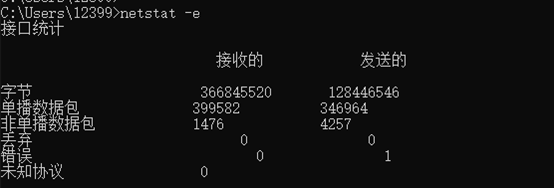
4.输入netstat -f后,执行后可以看到外部地址的完全限定域名。
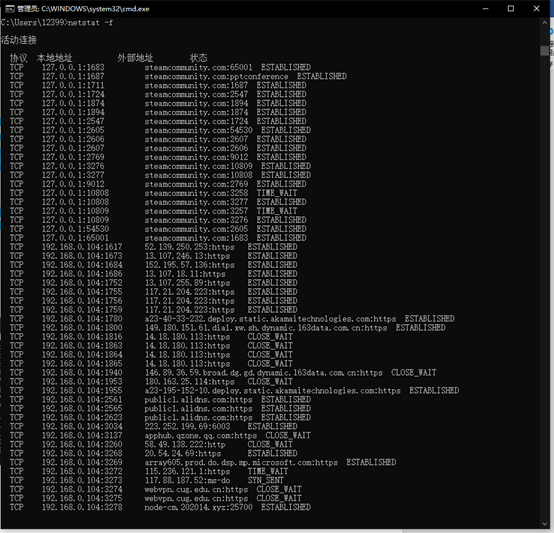
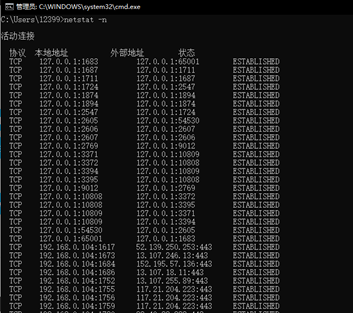
5.输入netstat -n后,执行后可以看到以数字形式显示地址和端口号。
6.输入netstat -o后,执行命令后显示拥有的与每个连接关联的进程 ID,可以看到每个活动连接使用的协议、本地地址、外部地址、状态和PID的信息。
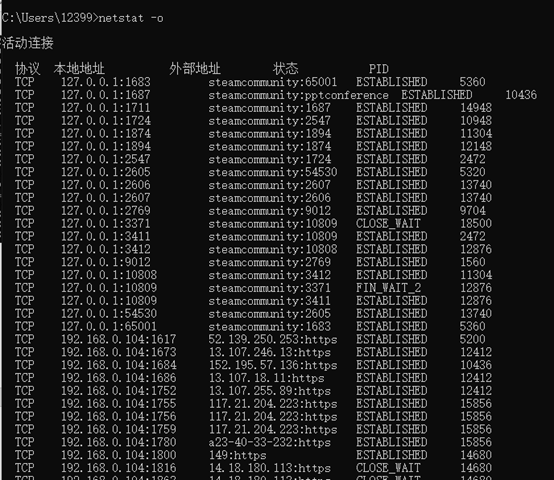
7.输入netstat -p TCP``(TCP可以换为其他协议)后,执行命令后显示UDP协议的连接。
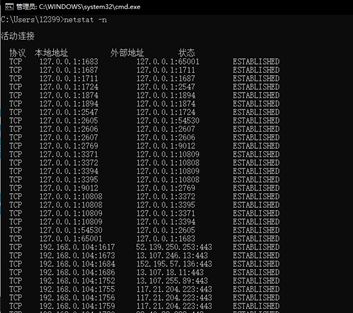
8.输入netstat -q后,执行命令后显示所有连接、侦听端口和绑定的非侦听 TCP 端口。
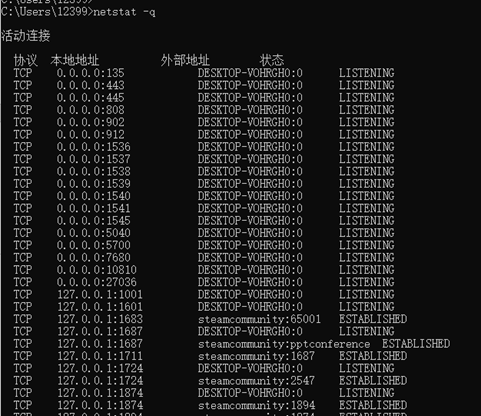
9.输入netstat -r,执行命令后显示该路由器的路由表。
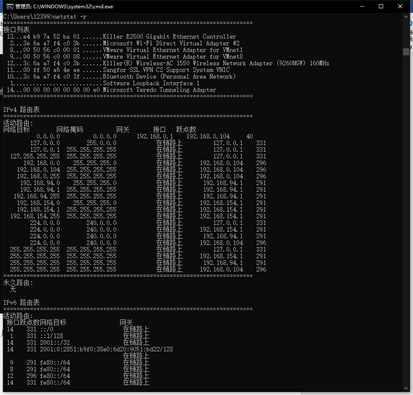
10.输入netstat -s,执行命令后显示每个协议的统计信息。
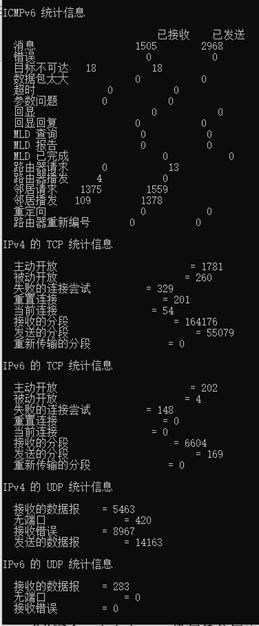
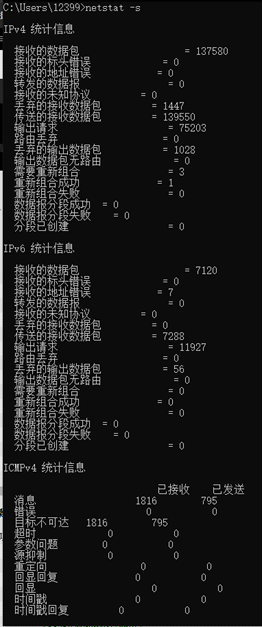 )
)
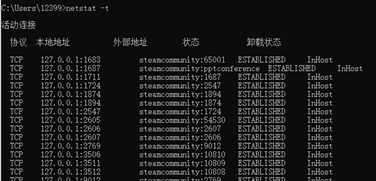
11.输入netstat -t,执行命令后显示当前连接卸载状态。
12.输入netstat - x,执行命令后显示 NetworkDirect 连接、侦听器和共享终结点,但是本台主机为空。

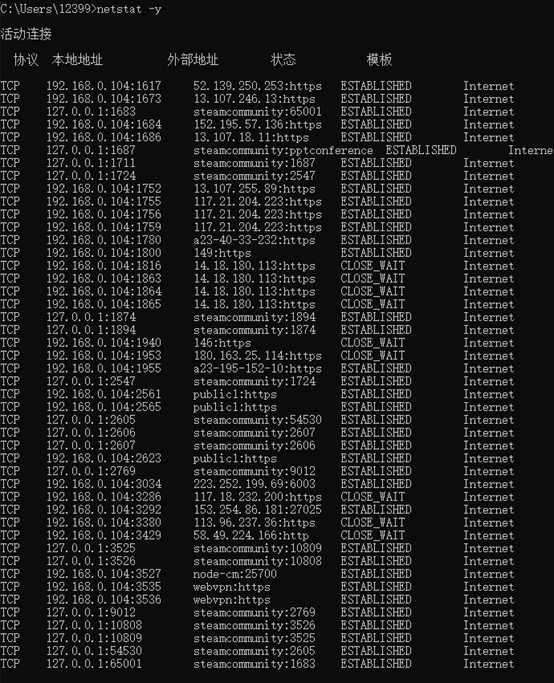
13.输入netstat -y,执行命令后显示所有连接的 TCP 连接模板。
14.输入netstat interval,执行命令后重新显示选定的统计信息。
9. route的相关操作
(1)实验步骤:
①打开电脑的cmd;
②在cmd中依次输入命令route print(add、change、delete),查看每个指令的具体功能;
(2)分析:
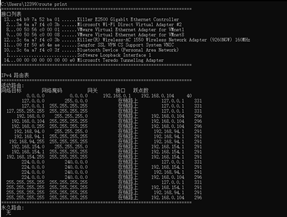
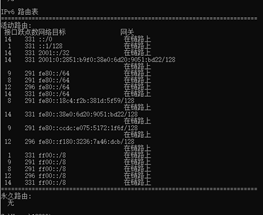
①输入route print后,显示当前路由器中路由表的信息。
 )
)
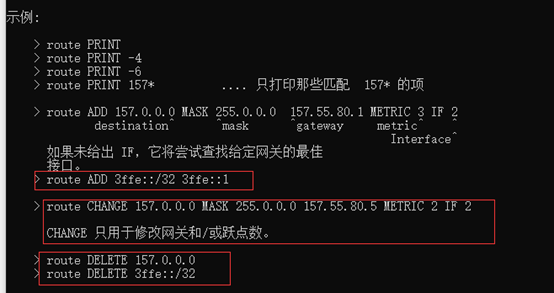
②输入route add后,将新的路由项目添加给路由表。
③输入route change后,修改数据报的传输路由。
③输入route delete后将某条路由表项从路由表中删除。输入指令后系统给出了操作示例。
10. nslookup
(1)实验步骤:
①打开电脑的cmd;
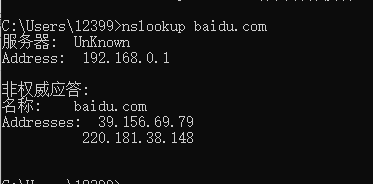
②在cmd中输入命令nslookup baidu.com,执行后查看对百度的输出结果。
(2)分析:
该指令用于测试或解决DNS服务器问题,该命令用两种模式:(1)非交互式模式;(2)交互式模式。可以看出百度的服务器给出了应答,地址为39.156.67.79和220.181.38.148。
11. ftp
(1)实验步骤:
①打开电脑的cmd;
②在cmd中输入命令ftp。
③输入open 192.168.0.1建立ftp连接。
④但是连接被拒绝,建立连接失败。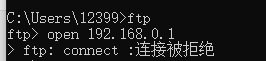
二、wireshark实验
1.TCP/IP格式
1.1 TCP报文格式
(1)实验步骤:
①开启 Wireshark Network Analyzer;
②选择WiFi进行捕获;
③过滤栏选择tcp进行过滤,停止捕获。
④选择第11条报文来分析TCP的报文格式。
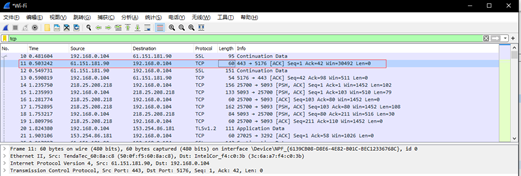
(2)分析:
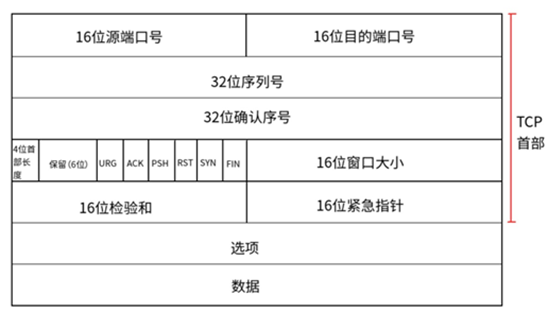
以这幅图的TCP报文格式对Wireshark捕获的分组11进行分析)
①这条TCP报文的源端口号为443,目的端口为5176。
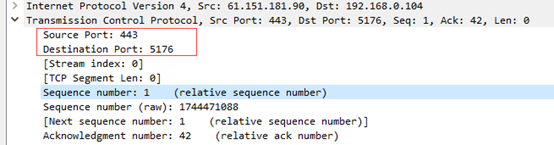
②由图可得现32位序列号,即Sequence number对应为67fa8430。
③由图可得现32位确认号,即Acknowledgment number对应为13faa7be。
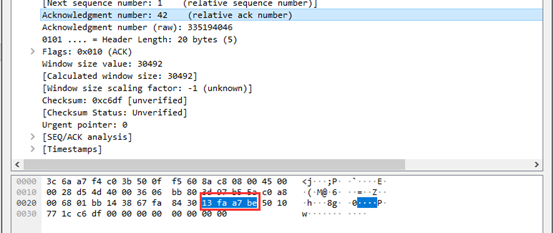
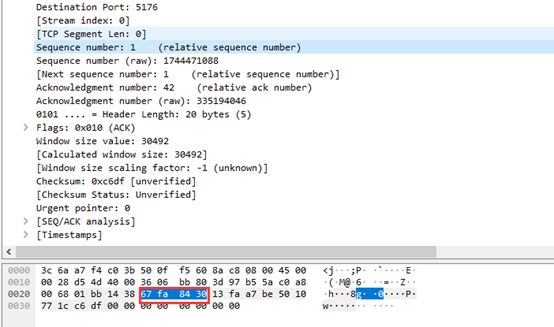
④ 由抓包图可以看到4位首部长度位0101,偏移量是 0101=5,TCP报文首部长度为5* 4 = 20字节。
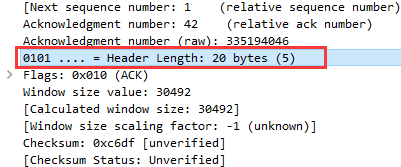
⑤保留位(6位)由跟在数据偏移字段后的 6 位构成。
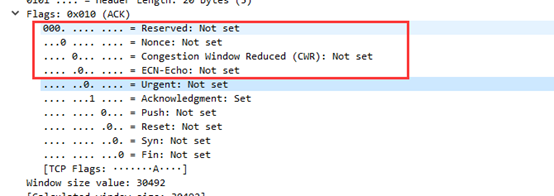
⑥这条报文的URG为0,ACK为1,PSH为0,RST为0,SYN为0,FIN为0。
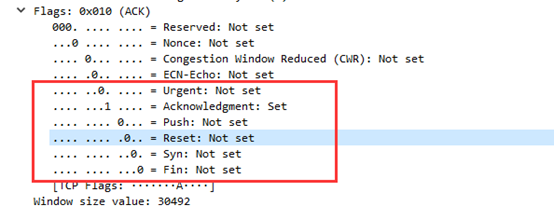
⑦窗口大小为30492。

⑧ 校验和(16位)为c6df。
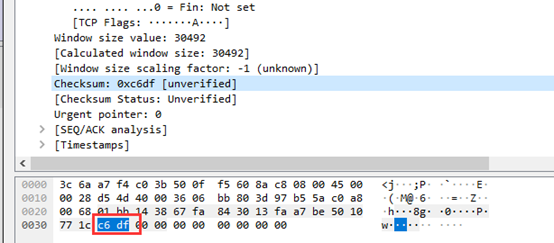
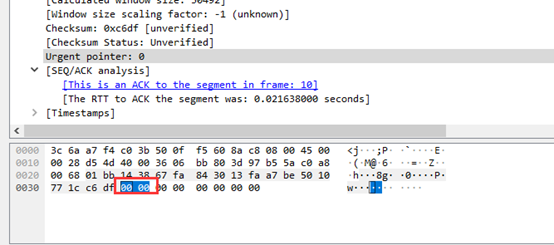
⑨紧急指针(16位)为0000。
1.2 IP报文格式
(1)实验步骤:
①开启 Wireshark Network Analyzer;
②选择WiFi进行捕获;
③过滤栏选择ip进行过滤,停止捕获。
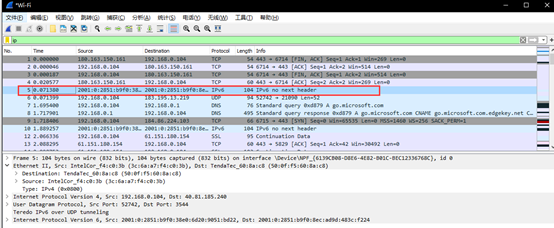
④选择第5条报文来分析TCP的报文格式。
(2)分析:
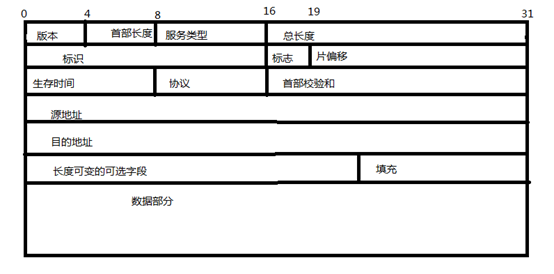
(以这幅图的IP报文格式对Wireshark捕获的分组5进行分析)
① 版本:从图中可以看出目前的IP协议版本号为4。

② 首部长度:由图可以看出首部长度为为0101,偏移量为0101=5,首部长度为20字节。

③ 总长度:由图可以看出IP报文的总长度为90。
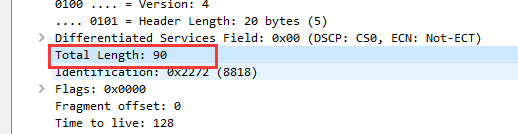
④ 标识:由图得出这是第8818个分片。
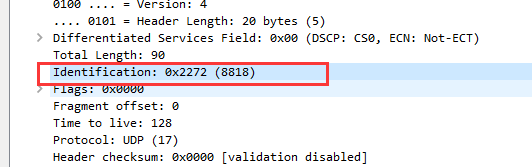
⑤ 标志:共3位。R、DF、MF三位。这个报文中三位都为0,DF位:为1表示不分片,为0表示分片。MF:为1表示“更多的片”,为0表示这是最后一片。
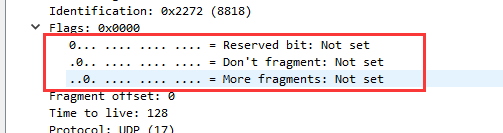
⑥ 片位移:这个报文显示片偏移为0。
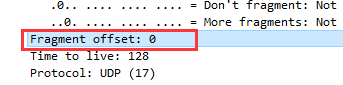
⑦ 生存时间:该报文显示生存时间为128。
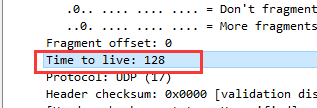
⑧ 协议:该报文显示使用的协议为UDP,代号为17。

⑨ 首部校验和:该报文显示的首部校验和为0000。
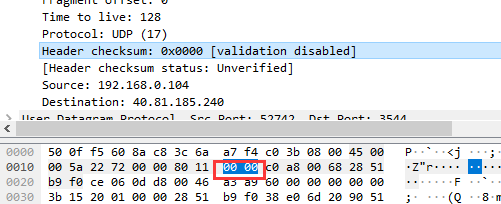
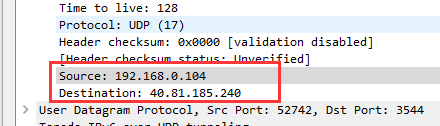
⑩ 源IP地址:该报文显示的源IP地址为192.168.0.104,即本机的IP地址。
目的IP地址:该报文显示的目的IP地址为40.81.185.240。
2. 三次握手分析
(1)TCP三次握手原理
三次握手,是指建立一个 TCP 连接时,需要客户端和服务器总共发送3个包。
第一次握手(SYN=1, seq=x):客户端发送一个 TCP 的 SYN 标志位置1的包,指明客户端打算连接的服务器的端口,以及初始序号X,保存在包头的序列号字段里。发送完毕后,客户端进入SYN_SEND 状态。
第二次握手(SYN=1,ACK=1,seq=y,ACKnum=x+1):服务器发回确认包(ACK)应答。即SYN 标志位和ACK标志位均为1。服务器端选择自己ISN序列号,放到Seq中,同时将确认序号(ACK)设置为客户的 ISN 加1,即X+1。发送完毕后,服务器端进入SYN_RCVD状态。
第三次握手(ACK=1,ACKnum=y+1):客户端再次发送确认包(ACK),SYN 标志位为0,ACK 标志位为1,并且把服务器发来 ACK 的序号字段+1,放在确定字段中发送给对方,并且在数据段放写ISN的+1。发送完毕后,客户端进入 ESTABLISHED 状态,当服务器端接收到这个包时,也进入 ESTABLISHED 状态,TCP 握手结束。
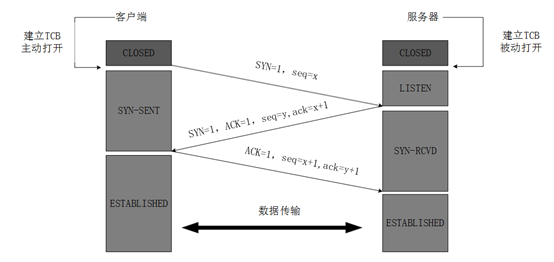
(2)TCP三次握手wireshark分析
打开wireshark,选择本地连接接口并开始抓包。打开浏览器,自动打开浏览器首页,页面加载完毕,停止抓包。观察封包列表,可以得到三次握手的数据,输入http进行过滤,wireshark抓到包:

目的地址为218.25.208.218,在通过过滤找到三次握手的信息。

由此我们可以验证HTTP的确是通过TCP建立连接的。
选中TCP封包,分别查看其封包详细信息,可以得到其端口信息、报文段长度、头部长度、校验和、ACK等。
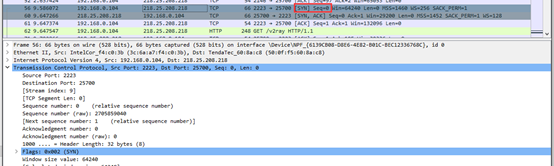
第一次握手数据包,可以看到客户端发送一个TCP,标志位为SYN,序列号为Seq=0, 代表客户端请求建立连接。如下图:
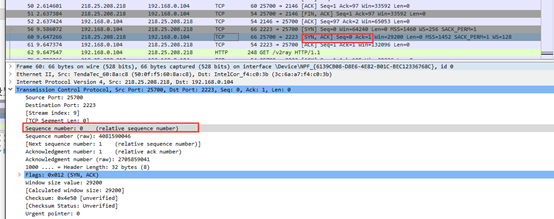
第二次握手数据包,可以看到服务器发回确认包, 标志位为 SYN,ACK. 将确认序号ACK设置为1.(Seq=0,Ack=1)如下图:
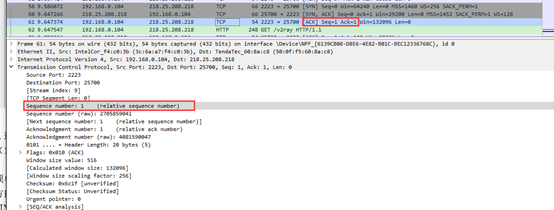
第三次握手数据包,可以看到客户端再次发送确认包(ACK) ,标志位为ACK,将sequence number+1(Seq=1,Ack=1).如下图:
使用wireshark的工具统计->流量图生成TCP连接的图像,根据时间找到这次连接的位置,此次三次握手正如下图红框中所示。

经过上述三次握手过程,即建立了HTTP连接。
3. 流量控制分析
(1)TCP流量控制原理
a.慢开始算法:
发送方维持一个叫做拥塞窗口cwnd的状态变量。拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。发送方让自己的发送窗口等于拥塞窗口,另外考虑到接受方的接收能力,发送窗口可能小于拥塞窗口。
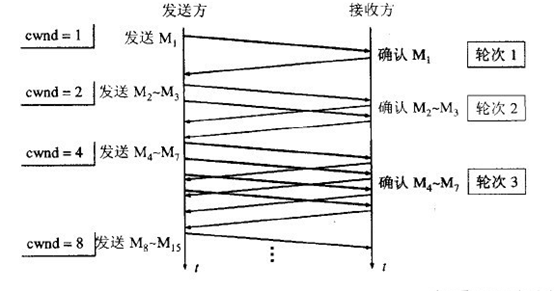
从图可以看到,一个传输轮次所经历的时间其实就是往返时间RTT,而且每经过一个传输轮次,拥塞窗口cwnd就加倍。
为了防止cwnd增长过大引起网络拥塞,还需设置一个慢开始门限ssthresh状态变量。ssthresh的用法如下:当cwnd<ssthresh时,使用慢开始算法。
当cwnd>ssthresh时,改用拥塞避免算法。
当cwnd=ssthresh时,慢开始与拥塞避免算法任意。
b. 拥塞避免算法:
拥塞避免算法让拥塞窗口缓慢增长,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1,而不是加倍。这样拥塞窗口按线性规律缓慢增长。
无论是在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞,就把慢开始门限ssthresh设置为出现拥塞时的发送窗口大小的一半。然后把拥塞窗口cwnd重新设置为1,执行慢开始算法。这样做的目的就是要迅速减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够时间把队列中积压的分组处理完毕。
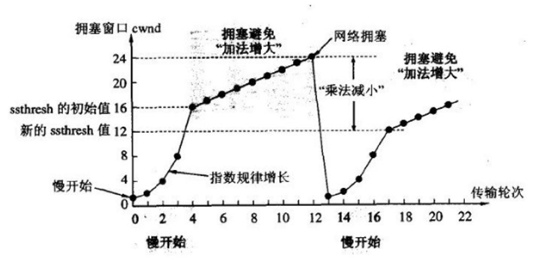
① 拥塞窗口cwnd初始化为1个报文段,慢开始门限初始值为16
②执行慢开始算法,指数规律增长到第4轮,即cwnd=16=ssthresh,改为执行拥塞避免算法,拥塞窗口按线性规律增长
③cwnd=24时,网络出现超时(拥塞),更新后的ssthresh=12,cwnd重新设置为1,并执行慢开始算法。当cwnd=12=ssthresh时,改为执行拥塞避免算法
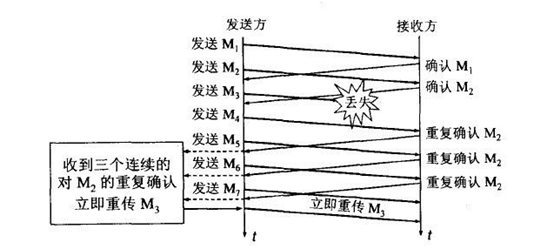
c. 快重传算法:
快重传要求接收方在收到一个失序的报文段后就立即发出重复确认,而不是等到自己发送数据时再确认。快重传算法规定,发送方一旦一次收到三个重复确认就应当立即重传对方尚未收到的报文段,而不必继续等待设置的重传计时器时间到期。如下图:
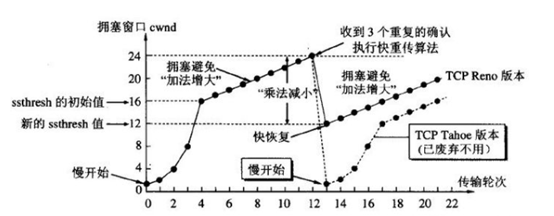
d. 快恢复算法:
当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把ssthresh门限减半。但是接下来并不执行慢开始算法。考虑到如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。所以此时不执行慢开始算法,而是将cwnd设置为ssthresh减半后的值,然后执行拥塞避免算法,使cwnd缓慢增大。
(2)TCP流量控制的wireshark分析
实验步骤:
①打开你的浏览器。输入:http://gaia.cs.umass.edu/wiresharklabs/alice.txt
将会看到 Alice in Wonderland 的文本版,然后暂时另存到电脑中;
②浏览器中输入:http://gaia.cs.umass.edu/wireshark-labs/TCP-wireshark-file1.html
③在屏幕中会显示:
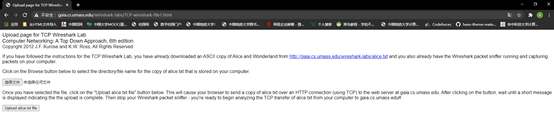
④用“浏览…”按钮选取你刚才保存的文件,先不按“ Upload alice.txt file”按钮;
⑤打开 Wireshark,开始包的捕获;
⑥再回到浏览器,按下“ Upload alice.txt file”按钮向 gaia.cs.umass.edu 服务器来上载文件;

⑦停止 Wireshark 的包捕获。
结果分析:
使用wireshark自带的绘图工具IO Graph绘图,我们可以窥见一个TCP慢启动的大致模型。
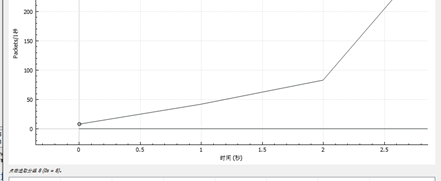
若向邮件服务器上传一个较大的文件,则曲线可能波动较大。
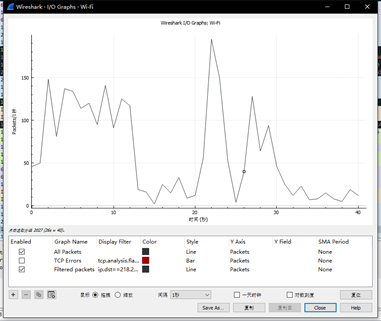
我们可以在上述较大文件上传抓取的数据包中找到慢启动过程:
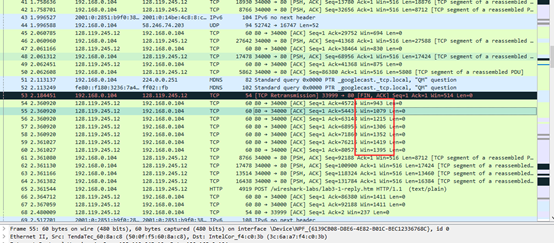
也可以发现乘法减少过程:
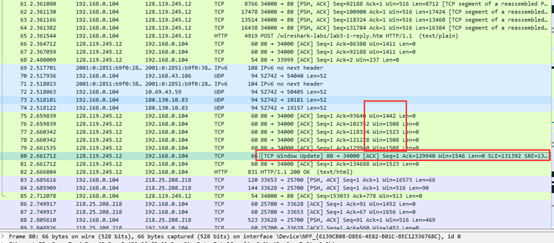

TCP window update表明TCP窗口清空了。
三、编程代码分析
1. TCP编程实验以及代码分析
实验环境:
Python3.8.6
Pycharm2020.2.2(专业版)
主机一台(作为用户端)
服务器一个(作为服务端)
(1)wireshark来分析TCP编程输出。
a.服务器端启动并等待连接。

b.用户端请求连接,并且连接成功。


c.建立连接前打开wireshark,选择Wi-Fi网卡接口进行抓包,观察封包的列表,可以看到三次握手的数据。
从报文可以看出用户端使用了随机端口号1971向端口号为1200的服务端发送了一个TCP,标志位为SYN,序列号Seq为0,这条报文说明客户端请求建立连接。
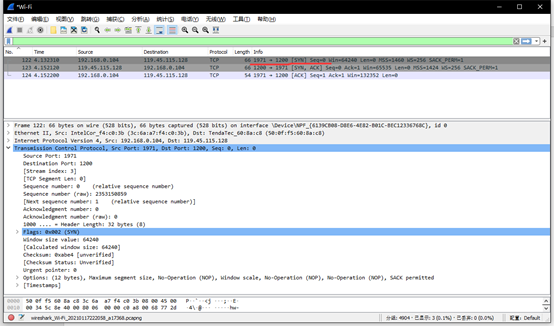
然后服务端发送了确认包,标志位为SYN,ACK,将确认序列号ACK设置为了1。
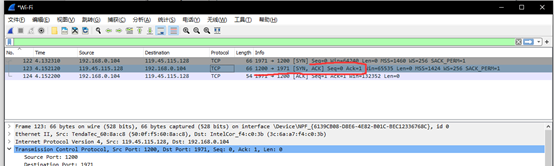
最后客户端又发送了确认包ACK,标志位为ACK,并且Seq增加了1从0变成了1。
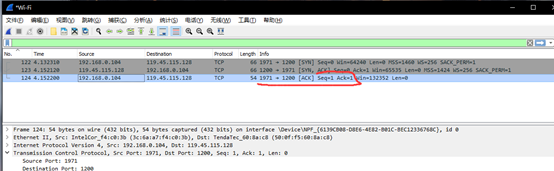
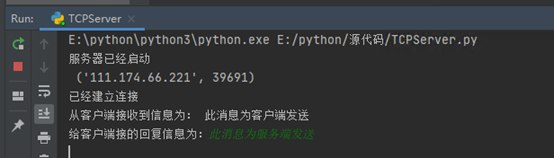
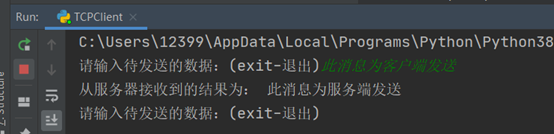
d.客户端发送消息:此消息为客户端发送。
客户端:

服务端收到信息:
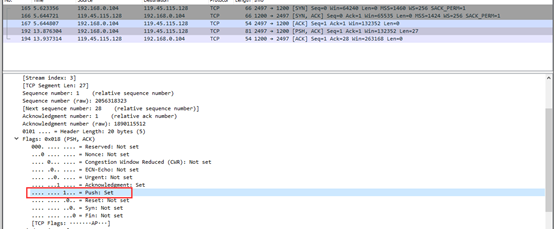
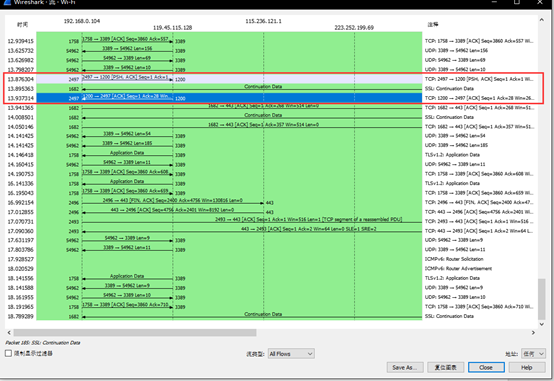
从Wireshark捕捉的TCP数据包,可以看到客户端发送了一条PSH为1的TCP报文段,尽快地交付给了接受应用进程,没有等到整个缓存都填满了后再向上交付。
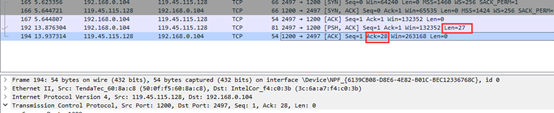
然后服务端向客户端发送了一个确认TCO数据包,标志位为ACK,由于上一条TCO数据包的长度len为27,所以此时的确认数据包中的ACK为28。
流量图为:
e.服务端回复信息:此消息为服务端发送
服务端发送信息:
客户端回复信息:
从Wireshark捕捉的TCP数据包,可以看到服务端发送了一条PSH=1的TCP报文段,尽快地交付接受应用进程,而不是等到整个缓存都填满后再向上交付。
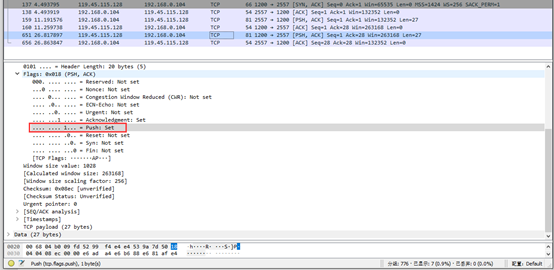
然后客户端向服务端发送了一个确认TCO数据包,标志位为ACK,由于上一条TCO数据包的长度len为27,所以此时的确认数据包中的ACK为28。
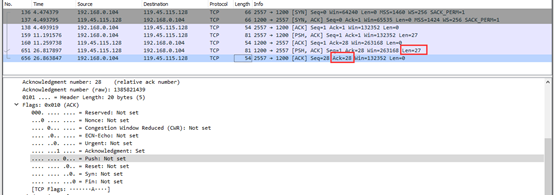
流量图为:
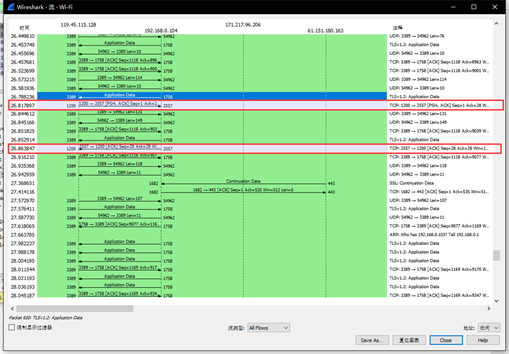
f.关闭程序后,wireshark捕获1200端口的数据包
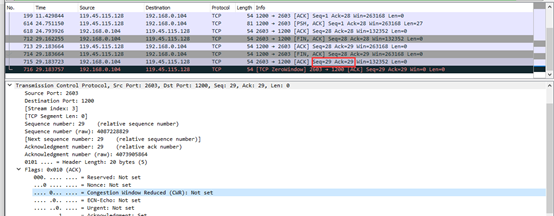
第一次挥手:客户端发送了一个Fin=1,Seq=28,ACK=28的报文,请求关闭客户机到服务器的数据传送。
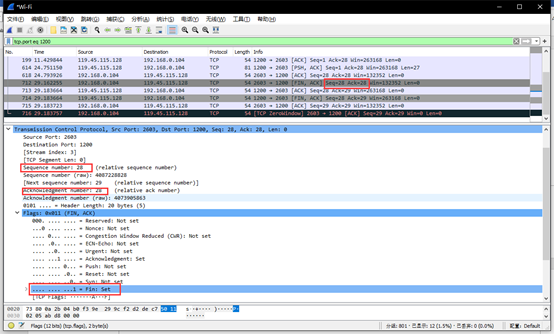
第二次挥手:服务端收到客户端的Fin,它发回了一个ACK,确认序号为收到得到序号+1,即ACK=28+1=29,Seq=28。
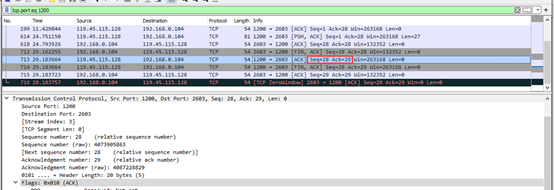
第三次挥手:客户端收到服务端发送的一个Fin=1,用于关闭服务端到客户端的数据传送,Seq=28,Ack=29;
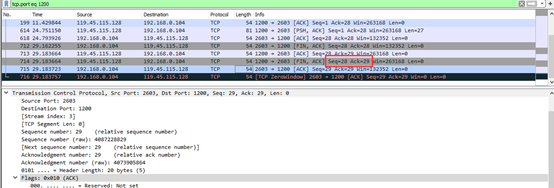
第四次挥手:客户端收到服务端发的Fin报文后,发送一个ACK给服务端,确认序号为收到序号+1,ACK=28+1=29,Seq=29,服务器进入关闭状态,完成了四次挥手。
(2)TCP客户端与服务端的代码分析
服务器端:
代码:
import socket分析:程序需要使用到底层网络接口库
代码:
host = "192.168.0.104"
port = 1200 分析:host中存服务端的主机ip地址192.168.0.104,port中存用于建立连接的端口号;
代码:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)分析:这一行创建了服务端的套接字,命名为s,第一个参数是指示底层网络使用的是IPv4, 第二个参数说明了这个套接字是SOCK_STREAM类型。这说明了这是一个TCP套接字;
代码:
s.bind((host, port))分析:这行代码将服务器的端口号port与该套接字关联起来。
代码:
s.listen(1) print(‘服务器已经启动’)
分析:这行让服务器聆听来自客户的TCO请求,参数1为请求连接的最大数量,启动后输 出“服务器已经启动”,服务端处于侦听状态,等待连接。
代码:
conn, addr = s.accept()
print('', addr)
print('已经建立连接')分析:执行这行代码说明有客户请求连接,程序为s调用了accept()方法,这在服务器中创 建了一个名为conn的新套接字由这个特定用户专用。客户与服务器完成了握手,在 用户得到套接字与服务器的套接字之间创建了一个TCP连接,借助于创建的TCP连 接,客户端与服务端可以通过这个连接互相发送字节。并且输出建立连接的ip地址 与端口号,输出“已经建立连接”告知用户连接已经建立完成。
代码:
while True:
try:
data = conn.recv(1024)
data = data.decode()
if not data:
break
print('从客户端接收到信息为:', data)
send = input('给客户端接的回复信息为:')
conn.sendall(send.encode())
except Exception as e:
print(e)分析:这是一个循环,用于服务端与客户端的信息传输与交流,用recv()捕获客户端发送 的信息并存在data中,先将data解码为字符串,如果data为空就退出循环,不为空 就输出从客户端接收到的信息内容,接着让用户输入服务端给客户端的回复信息,编 码后发送到客户端,并有一个异常处理的语句。通过这段代码可以实现客户端与服务 端的信息交流。
代码:
conn.close()
s.close()分析:关闭两个套接字,连接被释放。
客户端:
代码:
IP = '119.45.115.128'
port = 1200
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)分析:ip为服务端的ip地址,端口号与服务端的端口号一致,最后创建了客户的套接字, 称为s。第一个参数说明底层网络使用的是IPv4,第二个参数说明了这个套接字是 SOCK_STREAM类型。这表明了s是一个TCP套接字。
代码:
try:
s.connect((IP, port))
except Exception as e:
print(e)
print('服务器没有找到或未打开!')
sys.exit()分析:这包含了一个异常处理语句,如果连接没有建立成功就输出“服务器没有找到或未打 开!”),然后关闭。否者连接建立成功,s.connect((IP, port))语句成功执行,这行代码 发起了客户与服务端之间的TCO连接,connect()的参数是这条连接中服务器的地 址和端口号。这行代码执行后将进行三次握手,最后创建TCP连接。
代码:
while True:
try:
trigger = input("请输入待发送的数据:(exit-退出)")
if trigger == 'exit':
break
s.sendall(trigger.encode())
data = s.recv(1024)
data = data.decode()
print('从服务器接收到的结果为:', data)
except Exception as e:
print(e)分析:这仍然是一个循环用于客户端与服务端的信息交流,让用户先输入需要发送的数据, 如果输入为“exit”就退出循环,否则将发送的数据编码后发送到服务端,然后捕捉 服务端发回的信息并解码后输出从服务器端接收到的信息。其中包含一个异常处理语 句,如果捕捉到异常就输出。
代码:
s.close()分析:关闭了套接字,也就是关闭了客户和服务器之间的TCP连接。
2. UDP编程实验以及代码分析
实验环境:
Python3.8.6
Pycharm2020.2.2(专业版)
主机一台(作为用户端)
服务器一个(作为服务端)
(1)wireshark来分析UDP编程输出。
a.建立连接,分别启动服务端与客户端建立连接
服务端:
客户端:
b.客户端向服务端发送信息“此消息为客户端发送”,并收到服务器自动返回的信息
客户端:
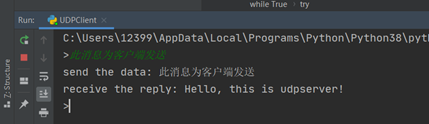
服务端:

whireshark抓到的包:
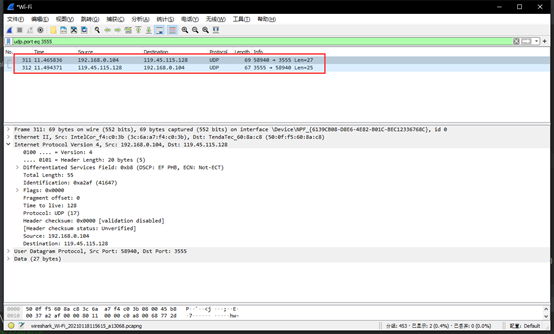
第一条为客户端向服务端发送的信息,第二条为服务端返回的信息。
(2)UDP客户端与服务端的代码分析
服务器端:
代码:
HOST = ''
PORT = 3555
BUFSIZ = 1024
ADDR = (HOST, PORT)分析:HOST为主机的ip地址即119.45.115.128,使用的端口号为3555,给BUFSIZ赋值1024 是将BUFSIZ作为一个常量后面控制单次传输的最大字节数,ADDR是将ip地址与端口 号封装起来。
代码:
udpServerSocket = socket(AF_INET, SOCK_DGRAM)
udpServerSocket.bind(ADDR)分析:第一行创建了服务端的套接字,命名为udpServerSocket,第一个参数说明了地址簇, AF_INET说明了底层网络使用了IPv4,第二个参数指示了该套接字是SOCK_DGRAM类 型的,这意味着他是一个UDP套接字。第二行将端口号3555与该服务器的套接字绑 定在一起。所以在UDP的服务端中代码显式地为该套接字分配了一个端口号,这样 任何人都可以向位于该服务器的IP地址的端口3555发送一个分组,这个分组会导向 这个套接字。
代码:
while True:
try:
data, addr = udpServerSocket.recvfrom(BUFSIZ)
print('来自主机 %s,端口: %s.' % addr)
print(data.decode('utf-8'))
reply = 'Hello, this is udpserver!'
udpServerSocket.sendto(reply.encode('utf-8'), addr)
except Exception as e:
print(e)分析:这是一个循环,这个循环让UDP的服务端无限接收处理来自客户的分组。一直等待 分组的到来。当分组到达这个服务器的套接字时,传输的数据信息存在了变量data 中,分组的源地址被存在了变量addr中。接受到信息后程序会先输出信息来自哪个 主机哪个端口,然后再输出信息。由于变量addr中包含了客户的IP地址和客户的端 口号,即为信息的返回地址,利用这个地址,服务器向源地址发送了一条reply信息 给源地址的主机。还有一句异常处理语句,如果发现异常就输出。
代码:
udpServerSocket.close()分析:这行命令时关闭套接字,服务端关闭不在收到信息。
客户端:
代码:
HOST = '119.45.115.128'
PORT = 3555
BUFSIZ = 1024
ADDR = (HOST, PORT)分析:HOST为服务器端的目的地址119.45.115.128,PORT为服务端开放用于信息交流的端 口号,给BUFSIZ赋值1024 是将BUFSIZ作为一个常量后面控制单次传输的最大 字节数,ADDR是将服务端ip地址与端口号封装起来。
代码:udpClientSocket = socket(AF_INET, SOCK_DGRAM)
分析:这一行创建了客户的套接字,命名为udpClientSocket,第一个参数表明了地址簇, AF_INET说明了底层网络用的是IPv4,第二个参数表明了这个套接字是SOCK_DGRAM 类型的,意味着这是一个UDP的套接字。
代码:
while True:
try:
data = input('>')
print('send the data: ' + data)
msg = data.encode('utf-8')
# 发送数据:
udpClientSocket.sendto(msg, ADDR)
# 接收数据:
print('receive the reply: ' + udpClientSocket.recv(BUFSIZ).decode('utf-8'))
except Exception as e:
print(e)分析:这个循环用于客户端与服务端的通讯,客户端要求用户先输入需要传输的数据内容, 然后编码后向服务器端发送这些数据,发送后服务器会回复,将服务端发送的信息解 码后输出出来。同样有一个异常处理语句,如果发现异常就将异常打印出来。
代码:
udpClientSocket.close()分析:改行关闭了套接字,关闭了这个进程。
3. OSPF编程实验以及代码分析
(1)OSFP原理
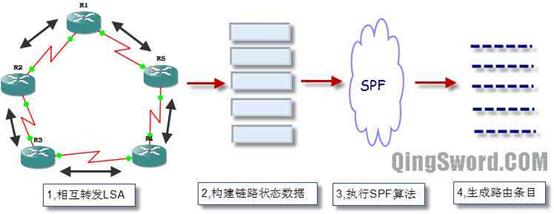
a.每台路由器学习激活的直接相连的网络。
b.每台路由器和直接相连的路由器互交,发送Hello报文,建立邻居关系。
c.每台路由器构建包含直接相连的链路状态的LSA(Link-State Advertisement,链路状态通告)。链路状态通告(LSA)中记录了所有相关的路由器,包括邻路由器的标识、链路类型、带宽等。
d.每台路由器泛洪链路状态通告(LSA)给所有的邻路由器,并且自己也在本地储存邻路由发过来的LSA,然后再将收到的LSA泛洪给自己的所有邻居,直到在同一区域中的所有路由器收到了所有的LSA。每台路由器在本地数据库中保存所有收到的LSA副本,这个数据库被称作”链路状态数据库(LSDB,Link-State Database)”
e.每台路由器基于本地的”链路状态数据库(LSDB)”执行”最短路径优先(SPF)”算法,并以本路由器为根,生成一个SPF树,基于这个SPF树计算去往每个网络的最短路径,也就得到了最终的路由表。
(2)OSPF Python 模拟实现
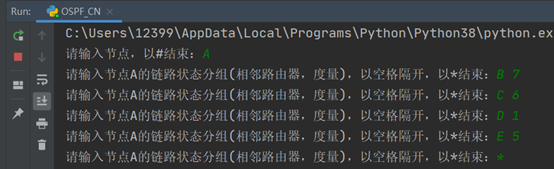
a.运行程序,向程序输入5个路由,为A,B,C,D,E这5个路由。
A的路由信息:
B的路由信息:
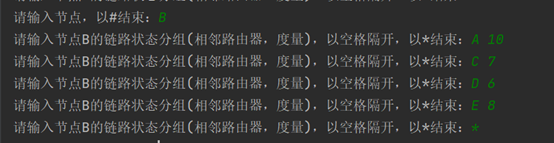
C的路由信息: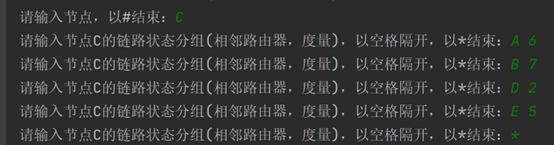
D的路由信息: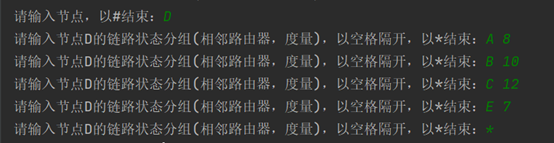
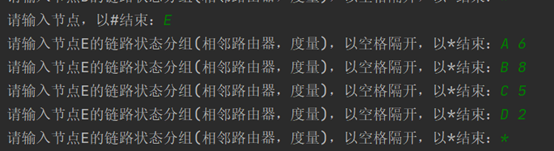
E的路由信息:
b.查看A,B,C,D,E的路由表:
A的路由表:
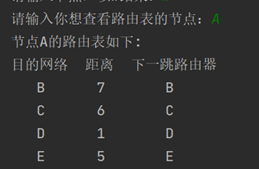
B的路由表:

C的路由表:
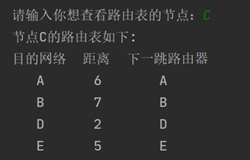
D的路由表:
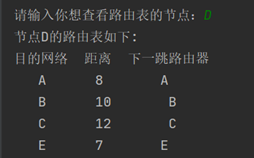
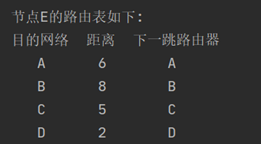
E的路由表:
(3)**代码分析**
代码:
def dijkstra(packets,node_route): #Dijkstra算法
table = [] #节点node_route的路由表
for key in packets[node_route]: #初始化table
if(packets[node_route][key]!=float('Inf')):
row=[key,packets[node_route][key],key,False]
else:
row=[key,packets[node_route][key],'无',False]
table.append(row)
count=0
while count<len(table):
temp=0 #temp用于保存当前table中距离最小的下标
min=float('Inf') #min用于记录当前的距离最小值
for i in range(len(table)):
if(table[i][3]==False and table[i][1]<min):
min=table[i][1]
temp=i
table[temp][3]=True #把temp对应的节点加入到已经找到的最短路径的集合中
count=count+1
for i in range(len(table)):
if(table[i][3]==False and packets[table[temp][0]][table[i][0]]!=float('Inf') and (table[temp][1]+packets[table[temp][0]][table[i][0]]<table[i][1])):
#如果新得到的边可能影响其它未访问的节点,那就更新它的最短距离和下一跳路由器
table[i][1]=table[temp][1]+packets[table[temp][0]][table[i][0]]
table[i][2]=table[temp][2]
table.sort(key=lambda x:x[0])
return table分析: 这为OSPF的核心算法,即Dijkstra算法,先定义一个空表table用于存储结点 的路由表,先对table进行初始化,对packets进行遍历,如果packets中存储的不是 +∞,那么临时变量row为一个列表信息(包括结点位置key,packets中存的跳数, 结点位置key,false);否则就是+∞,说明不可达,那么临时变量row的列表信息中存储的是(节点位置key,+∞,“无”(即没有信息),false),判断结束后将row存入 table列表的尾部。
先是一个大的循环,循环次数为列表的长度,先默认table中距离最小位置的下标 temp为0,默认最小值为+∞。接着进入一个小的循环,循环次数为列表的长度,如 果table中对应元素的第四个存储信息为false并且该元素的第二个存储信息(即跳数) 小于最小值min,那么更新最小值min为新的跳数,下标temp也更新为该元素的位 置。循环结束后把temp对应的节点加到已经找到的最短路径的集合中。控制最外层 循环的count增加1。
紧接着进入第二个小的循环,循环次数仍然为table列表的长度,如果同时满足 ①table中该该元素的第四个存储信息为false②packets中对应位置的跳数不为+∞ ③ table的temp位置存储的跳数与packets中存储的跳数相加后的和小于table该位置 (i)的跳数三个条件,就更新它的最短路径与下一条路由器。更新结束后结束循环。
最后对table进行排序,排序结束后返回存储路由表信息的table。
代码:
def main():
packets={} #所有的链路状态分组
nodes=[] #所有的节点
node=input('请输入节点,以#结束:')
while node!='#':
if(node not in nodes):
nodes.append(node)
else:
print('节点%s的链路状态分组已存在!' % node)
node = input('请输入节点,以#结束:')
continue
per={}
row=input('请输入节点%s的链路状态分组(相邻路由器,度量),以空格隔开,以*结束:' % node)
while row!='*':
row=row.split() #以空格分割输入的字符串
row=[int(x) if x.isdigit() == True else x for x in row] #把度量置为整型
if(row[1]<=0): #检查输入是否合理
print('输入违规!')
row = input('请输入节点%s的链路状态分组(相邻路由器,度量),以空格隔开,以*结束:' % node)
continue
if(row[0] in per): #避免重复
print('节点%s的链路状态分组中已有此项!' % node)
row = input('请输入节点%s的链路状态分组(相邻路由器,度量),以空格隔开,以*结束:' % node)
continue
per[row[0]]=row[1] #向节点node的链路状态分组中添加表项
row = input('请输入节点%s的链路状态分组(相邻路由器,度量),以空格隔开,以*结束:' % node)
packets[node]=per #向所有的链路状态分组中添加节点node的链路状态分组
node = input('请输入节点,以#结束:')
#将与每一节点未直接相邻的节点的度量置为无穷大(自身除外)
for key in packets:
for i in nodes:
if(i!=key and (i not in packets[key].keys())):
packets[key][i]=float('Inf')
while True:
node_route = input('请输入你想查看路由表的节点:')
table=dijkstra(packets,node_route)
print('节点%s的路由表如下:' % node_route)
print('目的网络 距离 下一跳路由器')
for row in table:
print(' '+row[0]+' '+str(row[1])+' '+row[2])
if __name__ == '__main__':分析: 此为执行的主函数,先定义一个空字典packets存储所有的链路状态分组,定义一 个nodes空列表存储所有的结点。先让用户输入一个结点,如果输入的是“#”,代表 输入节点已经结束。否则输入的不是“#”,判断这个节点是否在nodes列表中,如果 不在就加入nodes的尾部,如果在列表中就告诉用户列表中已存在,继续输入其他节 点。节点输入后再让用户输入这个结点的链路状态分组,如果输入的为“”就说明输 入完毕退出循环,否则不为“”,获取用户的非“*”输入的字符串后,将字符串以空 格进行切割,再把切割后的第二个元素的数据类型调整为整形。调整后判断输入是否 合法,如果跳数为≤0的数,告诉用户输入不合法请重新输入,合法后检查是否在per 中,如果存在就告诉用户状态分组已经有了请重新输入。确定合法且不重复后向节点 node的链路状态添加这一个表项。循环继续执行,执行相同的操作,知道用户输入“#” 后退出循环,结束输入。
遍历字典packets中每个节点,如果节点位置不等于key并且这个位置不是 packets的key列表的键,就将跳数设置为无穷大。这步操作是扫描每个结点的链路状 态分组,确保链路状态分组中有所有的其他节点,如果的链路状态分组中没有就加上 去并将跳数设置为+∞表示不可达。
接下来是输出路由表,这是一个循环,一次让用户获取一个节点的路由表。先执 行dijkstra算法确定最短路径并存储在table中,然后依次输出这个节点路由表的所有 信息,包括目的网络、距离和下一条路由器这些信息。
4. RIP编程实验以及代码分析
(1)RIP原理
RPI协议是一种内部网关协议(IGP),是一种动态路由选择协议,用于自治系统(AS)内的路由信息的传递。RIP协议基于距离矢量算法(DistanceVectorAlgorithms),使用“跳数”来衡量到达目标地址的路由距离。这种协议的路由器只关心自己周围的世界,只与自己相邻的路由器交换信息,范围限制在15跳(15度)之内。获取新的路由信息时:
a. 对本路由表中已有的路由项,当发送报文的网关相同时,不论跳数增大还是减少,都更新该路由表项的跳数。
b. 对本路由表中已有的路由项,当发送报文的网关不同时,只有在跳数减少时才更新该路由表项。
c. 对本路由表中不存在的路由项,在度量小于不可达的跳数时,在路由表中增加该路由项目。
(2)RIP Python 模拟实现
a.输入当前路由表行数为5.

b.输入路由表的内容(格式为【目的网络,距离,下一条】
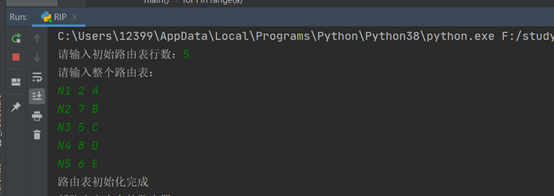
c.输入新路由表来自的路由器A以及新路由表(格式为【目的网络,跳数】)

d. 获取更新后的路由表
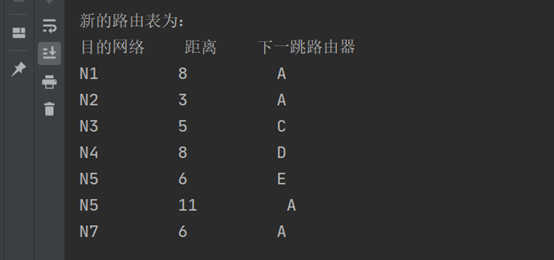
(3)**代码分析**
代码:
class Net:
def __init__(self,DesNet,Dis,NextHoop):
self.DesNet = DesNet #目的网络
self.Dis = Dis #距离
self.NextHoop = NextHoop #下一跳
self.next = None分析:这是一个节点类,数据元素包括目的网络、距离、下一条的网络和下一个节点的位置。
代码:
class Link:
# 构造函数
def __init__(self):
self.head = Net(None,None,None) # 头节点为空
self.tail = self.head
self.size = 1分析:为链路link类的构造函数,使用了带附加头节点链表的数据结构,初始头结点为空, 尾节点指向头结点,节点数为1(空的头结点)。
代码:
# 添加节点
def add(self,DesNet,Dis,NextHoop):
net = Net(DesNet,Dis,NextHoop) # 创建新节点
self.tail.next = net # 尾节点的下一个节点为新节点
self.tail = net # 尾节点为新节点
self.size = self.size + 1分析:这个函数的作用为添加节点,先创建一个新节点(参数DesNet为目的网络,Dis为 距离,NextHoop为下一跳),让尾节点的下一个节点为这个新节点,此时尾节点为这 个新节点,节点个个数增加1。
代码:
# 插入节点(此节点作为第index个节点)
def insert(self, DesNet, Dis, NextHoop, index):
if (index > self.size):
print('链表还没有这么长哟!请输入小一点的整数......')
else:
net = self.head
insert_net = Net(DesNet, Dis, NextHoop)
for i in range(index - 1):
net = net.next # 推进到要插入的位置
insert_net.next = net.next
net.next = insert_net
self.size = self.size + 1分析:这个函数的作用为在index位置插入节点,如果插入位置index大于节点个数,那么 无法插入,小于节点个数时,让“指针”net指向头结点,根据信息创建需要插入的 节点insert_net,再通过循环将net推进到需要插入的位置,此时插入节点insert_net 的下一个节点为net的下一个节点,net的下一个节点变为插入节点insert_net,节 点的个数增加1个。
代码:
# 删除节点(索引为index)
def delete(self, index):
if (index > self.size):
print('链表还没有这么长哟!请输入小一点的整数......')
else:
net = self.head
for i in range(index - 1):
net = net.next
temp = net.next
net.next = temp.next
self.size = self.size - 1分析:这个函数的功能为删除位置index的节点,如果位置index大于链表长度无法删除, 小于链表长度时,让“指针”net指向链表的头结点,然后通过循环将net推进到需 要删除的位置,用临时变量temp存储net的下一个节点,然后net的下一个节点改 编为temp的下一个节点,节点的个数减少1,删除完成。
代码:
# 改变指定节点的数据
def change(self, DesNet, Dis, NextHoop, index):
if (index > self.size):
print('链表还没有这么长哟!请输入小一点的整数......')
else:
net = self.head
for i in range(index): # 推进到要改变节点的位置
net = net.next
net.DesNet = DesNet
net.Dis = Dis
net.NextHoop = NextHoop分析:这个函数的作用为改变指定节点位置inedx的数据,如果位置index大于链表长度无 法删除。小于链表长度时,让“指针”net指向链表的头结点,然后通过循环将net 推进到需要改变节点的位置,将该节点的目的地址换为新的目的地址,距离换为新的 距离,下一跳地址更新为新的下一条地址。
代码:
# 返回节点的数据
def getData(self, index):
if (index > self.size): # 判断是否超过链表的长度
print('链表还没有这么长哟!请输入小一点的整数......')
else:
net = self.head
for i in range(index):
net = net.next
return [net.DesNet, net.Dis, net.NextHoop]分析:该函数的作用为返回位置为index的数据,如果果位置index大于链表长度无法返回。 小于链表长度时,让“指针”net指向链表的头结点,然后通过循环将net推进到需要 返回节点的位置,然后返回该节点的目的网络,距离和下一跳网络的信息。
代码:
# 返回节点的长度
def getSize(self):
return self.size分析:该函数的作用为返回节点的长度,直接返回节点的个数即可。
代码:
def length(self):
# 获取这个链表的长度
count = 0
cur = self._head
while cur != None:
count += 1
cur = cur.next
return count分析:这个函数的作用为获取链表的长度,初始计数的长度count为0,指针cur指向头结 点,然后遍历指针,每遍历一个节点count增加1,遍历结束后返回count值就是返 回链表的长度。
代码:
def main():
table = Link() # 初始路由表
NewTable = Link() # 来自某个路由器的路由表
FinalTable = Link() # 最终形成的路由表
temptable1 = []
temptable2 = []
a = int(input('请输入初始路由表行数:'))
print('请输入整个路由表:')
for i in range(a):
DesNet, Dis, NextHoop = input().split()
table.add(DesNet, Dis, NextHoop)
FinalTable.add(DesNet, Dis, NextHoop)
print('路由表初始化完成')
b = input('新路由表来自的路由器:')
c = int(input('新路由表的行数:'))
print('请输入新路由表的信息:')
for i in range(c):
DesNet, Dis = input().split()
Dis = int(Dis) + 1
NewTable.add(DesNet, Dis, b)
for i in range(c):
if i == 0: continue
count = 0
for j in range(a):
if j == 0: continue
temptable1 = NewTable.getData(i)
temptable2 = FinalTable.getData(j)
if temptable1[0] == temptable2[0]: # 如果目标网络相同
if temptable1[2] == temptable2[2]: # 如果目标网络和下一跳均相同
FinalTable.change(temptable1[0], temptable1[1], temptable1[2], j)
if temptable1[2] != temptable2[2]: # 如果目标网络一致,下一跳不同
if int(temptable1[1]) < int(temptable2[1]):
FinalTable.change(temptable1[0], temptable1[1], temptable1[2], j)
else:
continue
if temptable1[0] != temptable2[0]:
count = count + 1
if int(count) == int(a) - 1:
FinalTable.add(temptable1[0], temptable1[1], temptable1[2])
print('新的路由表为:')
print('目的网络 距离 下一跳路由器')
for i in range(FinalTable.size):
if i == 0: continue
data = FinalTable.getData(i)
print(str(data[0]) + ' ' + str(data[1]) + ' ' + str(data[2]))
if __name__ == '__main__':
main()分析: 这位函数执行的主体,先初始化一个路由表,新路由表(来自某个路由器的路 表),最终形成的路由表这三个Link类型的变量,创建两个临时列表temptable1和 temptable2。然后让用户输入初始路由表的行数,再让用户输入整个路由表,遍历用 户输入的整个路由表,将每行进行切片处理,第一个数据为目的网络DesNet,第二个 数据为距离Dis,第三个数据为NextHoop下一条网络,切片处理一组数据,就将处理 完成的数据加入到初始路由表table和最终路由表FinalTable的尾部。处理完成后输 出路由表的初始化完成。
接着让用户输入新路由表来自的路由器和新路由表的行数,接着输入新路由表的 所有信息,遍历用户输入的整个新路由表,将每行进行切片处理,切片后的第一个数 据为目的网络DesNet,第二个数据为跳数Dis,然后将跳数增加1,在新路由表中加 入新的信息(包含目的网络,跳数,新路由表来自的路由器)。
执行一个循环(i为循环的轮次),循环次数为新路由表的行数,如果i为0就跳 过执行下一次循环,将count初始化为0,再执行一个内层循环(j为循环的轮次), 执行的次数为原来路由表的行数,临时变量temptable1存储新路由表NewTable第I 个位置的数据,临时变量temptable2存储最终路由表FinalTable第j个位置的数据信 息。如果temptable1的目标网络与temptable2的目标网络相同执行,分类后执行两 种操作:如果temptable1的下一条地址与temptable2的下一跳地址相同,最终路由 表的这条信息更新为新路由表中的信息;如果两者的下一跳网络不同并且temptable1 的跳数小于temptable2的跳数,也将最终路由表的这条信息更新为新路由表中的信 息,如果temptable1的跳数大于temptable2的跳数就不需要更新。如果temptable1 与temptable2的目的网络不同,那么count增加1,如果count的值与初始路由表行 数-1的值相等,说明之前的路由表没有这条信息,就在最终路由表的尾部加入这条路 由。
更新完毕后输出新的路由表,依次遍历最终路由表的信息,每条信息都输出目的 网络、距离和下一条路由器,将更新后的路由表呈现给用户。



